内置 Dashboards
Grafana UI#
Grafana 允许你查询、可视化、预警和了解你的指标。
要查看时间序列数据可视化的默认仪表盘,请访问 Grafana UI。
自定义 Grafana#
要查看和自定义支持 Grafana 仪表盘的 PromQL 查询,请参见本页
持久化 Grafana 仪表盘#
要创建一个持久的 Grafana 仪表盘,请参见本页
访问 Grafana#
关于 Grafana 的基于角色的访问控制的信息,见本节
Alertmanager UI#
当安装 rancher-monitoring 后,将自动部署 Prometheus Alertmanager UI,该 UI 允许你查看你的告警和当前 Alertmanager 配置。
本节假设熟悉监控组件如何协同工作。关于 Alertmanager 的更多信息,见本节。
访问 Alertmanager UI#
Alertmanager UI 可以看到最近发生的告警。
前提条件:必须安装
rancher-monitoring应用程序。
要查看 Alertmanager UI ,请进入集群资源管理器。在左上角,点击集群资源管理器>监控。然后点击Alertmanager.
结果: Alertmanager UI 在一个新的标签中打开。关于配置的帮助,请参考官方 Alertmanager 文档。
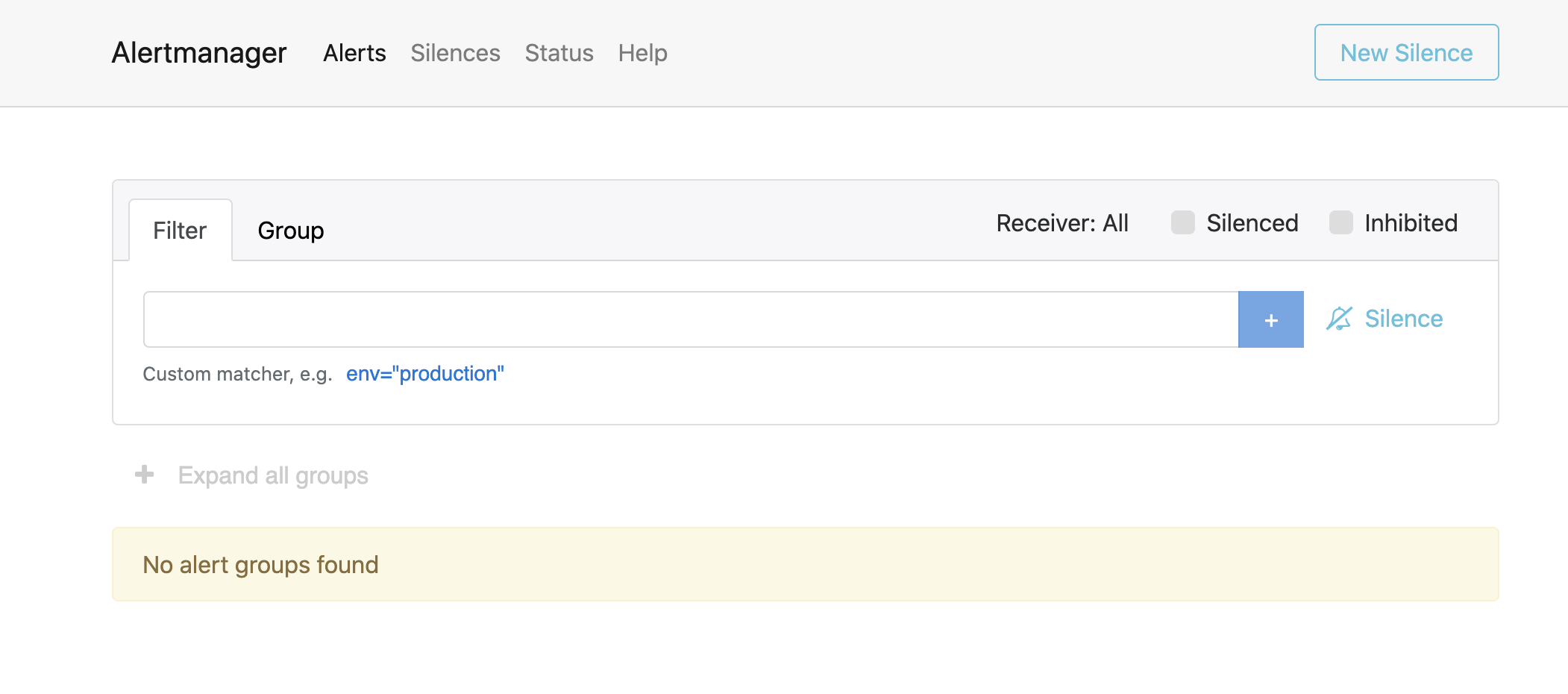
查看默认告警#
要查看默认触发的告警,请进入 Alertmanager UI 并点击展开所有组。
Prometheus UI#
默认情况下,kube-state-metrics 服务为监控应用提供了大量关于 CPU 和内存利用率的信息。这些指标涵盖了跨命名空间的 Kubernetes 资源。这意味着,为了看到一个服务的资源指标,你不需要为它创建一个新的 ServiceMonitor。因为数据已经在时间序列数据库中,你可以去 Prometheus UI ,运行 PromQL 查询来获得信息。同样的查询可以用来配置一个 Grafana 仪表盘,以显示这些指标随时间变化的图表。
要使用 Prometheus UI ,请安装 rancher-monitoring。然后进入集群浏览器。在左上角,点击集群浏览器>监控。然后点击Prometheus 图表。
Prometheus Graph UI:
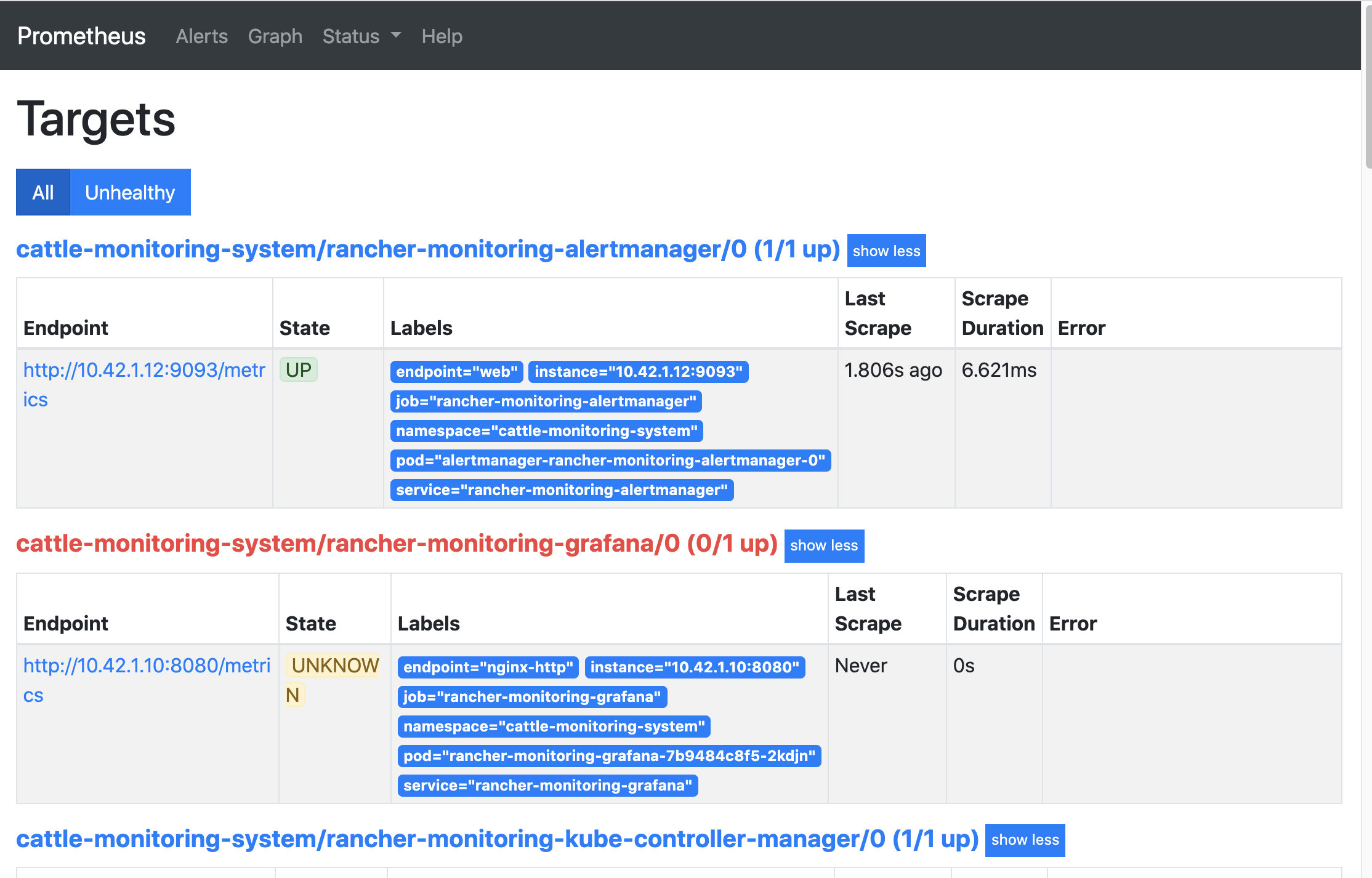
查看 Prometheus Targets#
要查看你正在监控的服务,你需要查看你的 targets。Targets 是由 ServiceMonitors 和 PodMonitors 设置的,作为抓取指标的来源。你不需要直接编辑 targets,但是 Prometheus UI 可以让你看到所有正在被抓取的指标来源的概况。
要查看 Prometheus Targets,请安装 rancher-monitoring。然后进入集群浏览器。在左上角,点击集群浏览器>监控。然后点击Prometheus Targets。
Prometheus UI 中的 Targets:
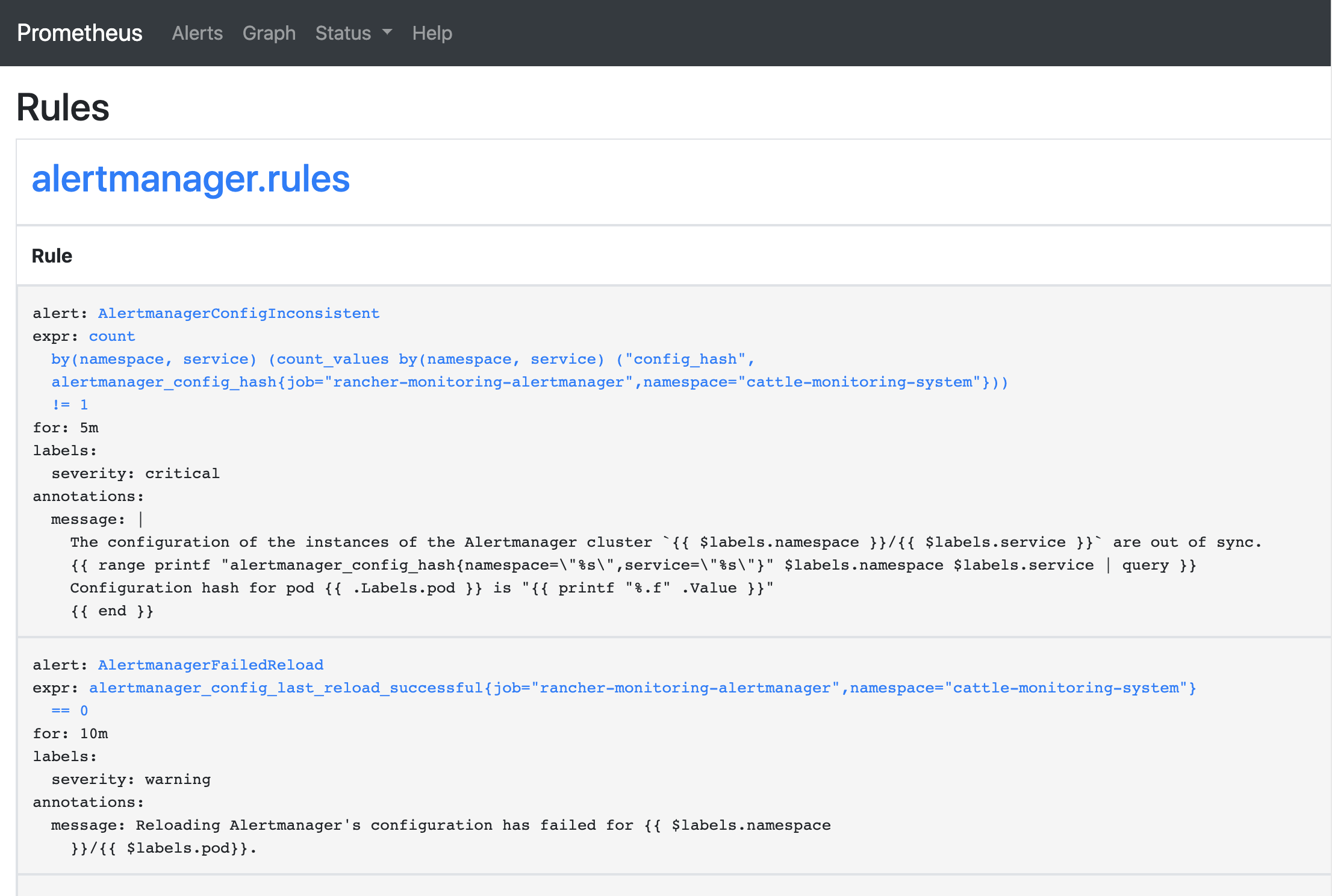
查看 PrometheusRules#
当你定义一个规则(在 PrometheusRule 资源的 RuleGroup 中声明)时,规则本身的规格包含标签,这些标签被 Alertmanager 用来计算哪个路由应该收到某个告警。
要查看 PrometheusRules,请安装 rancher-monitoring。然后进入群组资源管理器。在左上角,点击群组资源管理器>监控。然后点击Prometheus 规则。
你也可以在 Prometheus UI 中看到这些规则。
Prometheus UI 中的规则: